Swish Vs Relu : Swish Vs Mish: Latest Activation Functions - Krutika Bapat ... - Experiments show that swish overperforms relu for deeper networks.
Dapatkan link
Facebook
X
Pinterest
Email
Aplikasi Lainnya
Swish Vs Relu : Swish Vs Mish: Latest Activation Functions - Krutika Bapat ... - Experiments show that swish overperforms relu for deeper networks.. Relu > scaled swish > swish > selu in this experiment, we added scaled swish into comparison (i found scaled swish in a reddit thread that someone said it performs better than original one). Relu function (glorot et al., 2011) has proven much more suitable. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. Utilisons mish dans nos projets. Experiments show that swish overperforms relu for deeper networks.
Rustle and swish are synonymous, and they have mutual synonyms. Experiments show that swish overperforms relu for deeper networks. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. 4 mise en application : On the reuters newswire topic classification task.
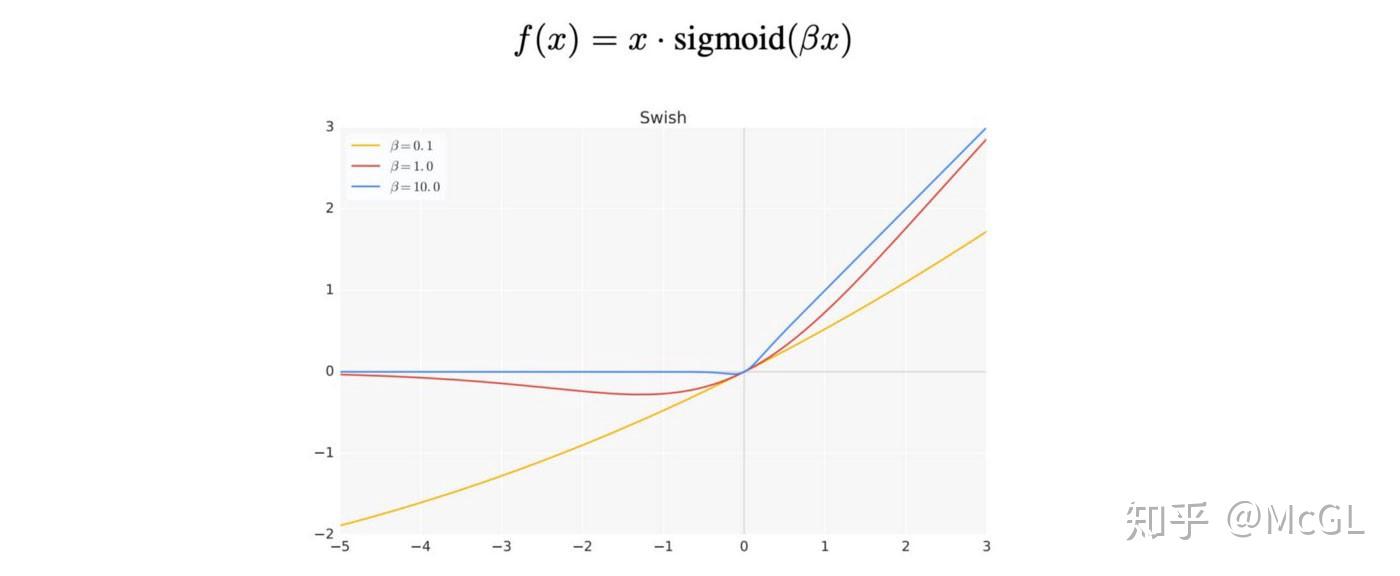
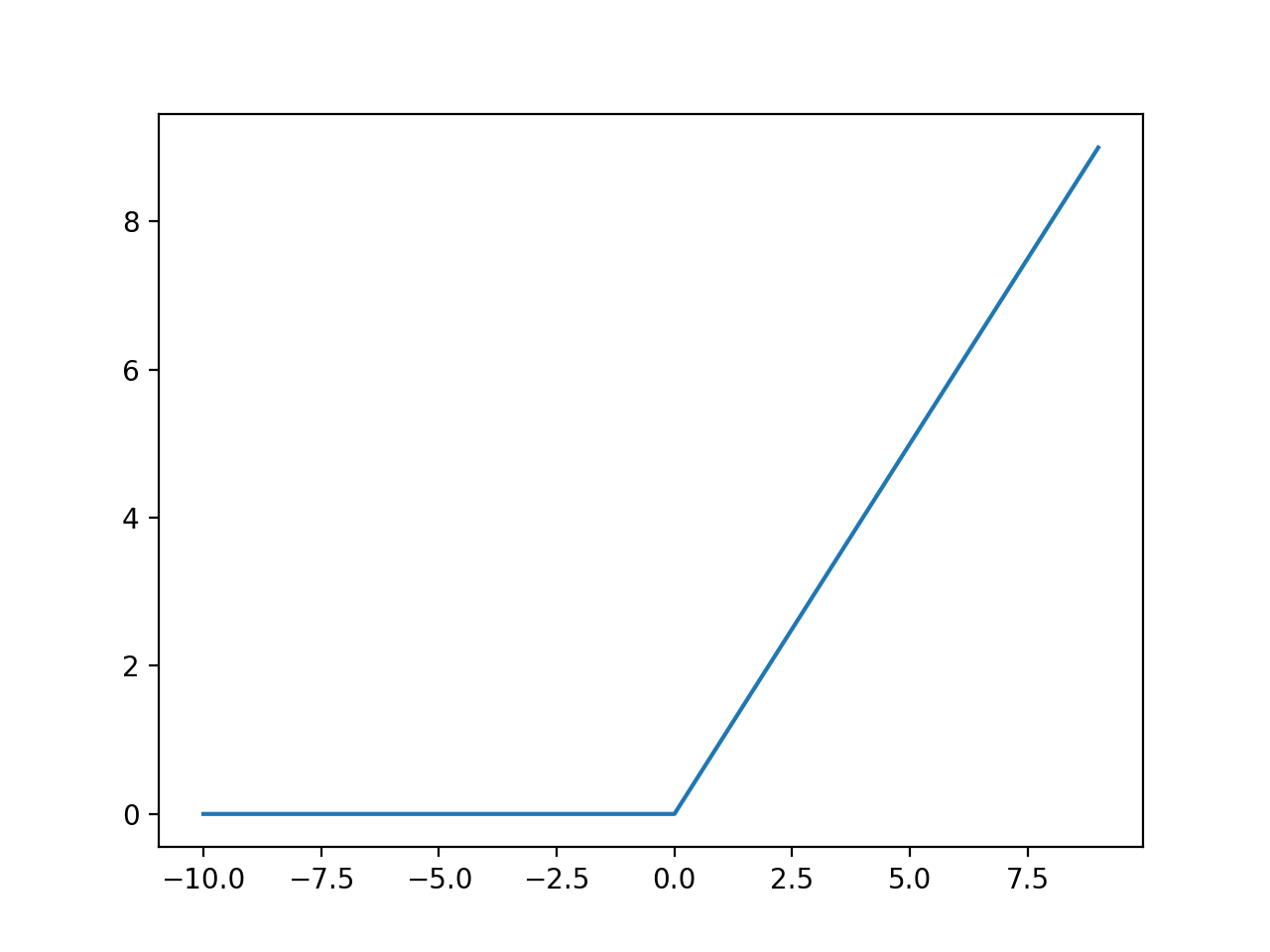
YOLOv4 - 知乎 from pic1.zhimg.com The swish function is a mathematical function defined as follows: Relus consistently beat swish on accuracy. (2020) benchmarking comparison of swish vs. Having a by definition, relu is a monotonous and a smooth function as shown in fig. Problemin türüne bağlı olmakla birlikte, giriş vektörüne batch normalization. Like relu, swish is unbounded above and bounded below. The authors find that by substituting the relu units for swish units, there is significant improvement over relu as the number of layers increases from 42. Crown | relu, mish & swish loss landscapes, 200th epoch, resnet 20 comparison study between the loss landscapes of the relu, mish and swish activation.
The authors find that by substituting the relu units for swish units, there is significant improvement over relu as the number of layers increases from 42.
Activation function used by the yolo architecture is hard swish a variation of swish proposed by google brains in 2017, it looks very identical to relu but unlike relu it is relu vs swish source. The leaky relu and elu functions both try to account for the fact that just returning 0 isn't great for training the network. Utilisons mish dans nos projets. | hock hung chieng • noorhaniza wahid • pauline ong • sai raj kishore perla. Like relu, swish is unbounded above and bounded below. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. Experiments show that swish overperforms relu for deeper networks. Problemin türüne bağlı olmakla birlikte, giriş vektörüne batch normalization. 4 mise en application : Having no bounds is desirable for activation functions as it avoids problems when gradients are nearly zero. Conventionally, relu has been the most popular activation function due to its gradient preserving property (i.e. Crown | relu, mish & swish loss landscapes, 200th epoch, resnet 20 comparison study between the loss landscapes of the relu, mish and swish activation. There is a large difference between training times even if swish performs better than relus on a problem, the time required to train a good model will be.
Like relu, swish is bounded below (meaning as x approaches negative infinity, y approaches some constant value) but unbounded above (meaning as x approaches positive infinity, y approaches infinity). Advantages over relu activation function: Like relu, swish is unbounded above and bounded below. | hock hung chieng • noorhaniza wahid • pauline ong • sai raj kishore perla. On the reuters newswire topic classification task.
Swish Vs Mish: Latest Activation Functions - Krutika Bapat ... from raw.githubusercontent.com Advantages over relu activation function: Like relu, swish is bounded below (meaning as x approaches negative infinity, y approaches some constant value) but unbounded above (meaning as x approaches positive infinity, y approaches infinity). Experiments show that swish overperforms relu for deeper networks. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. Relu function (glorot et al., 2011) has proven much more suitable. Relu > scaled swish > swish > selu in this experiment, we added scaled swish into comparison (i found scaled swish in a reddit thread that someone said it performs better than original one). 4 mise en application : | hock hung chieng • noorhaniza wahid • pauline ong • sai raj kishore perla.
Rustle and swish are synonymous, and they have mutual synonyms.
4 mise en application : Where β is either constant or a trainable parameter depending on the model. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. (2020) benchmarking comparison of swish vs. Why the swish activation function. Relu > scaled swish > swish > selu in this experiment, we added scaled swish into comparison (i found scaled swish in a reddit thread that someone said it performs better than original one). Having no bounds is desirable for activation functions as it avoids problems when gradients are nearly zero. Activation function relu leaky relu swish deep neural networks. Problemin türüne bağlı olmakla birlikte, giriş vektörüne batch normalization. Like relu, swish is bounded below (meaning as x approaches negative infinity, y approaches some constant value) but unbounded above (meaning as x approaches positive infinity, y swish vs. The leaky relu and elu functions both try to account for the fact that just returning 0 isn't great for training the network. These days two of the activation functions mish and swift have outperformed many of the previous results by relu and leaky relu specifically. Having a by definition, relu is a monotonous and a smooth function as shown in fig.
| hock hung chieng • noorhaniza wahid • pauline ong • sai raj kishore perla. Rustle and swish are synonymous, and they have mutual synonyms. Where β is either constant or a trainable parameter depending on the model. The swish function is a mathematical function defined as follows: Why the swish activation function.
Swish Vs Mish: Latest Activation Functions - Krutika Bapat ... from raw.githubusercontent.com Pourtant, comme vous le verrez en fin d'article, il y a des cas dans lesquels relu ou même swish sont meilleurs que mish. Like relu, swish is unbounded above and bounded below. These days two of the activation functions mish and swift have outperformed many of the previous results by relu and leaky relu specifically. Like relu, swish is bounded below (meaning as x approaches negative infinity, y approaches some constant value) but unbounded above (meaning as x approaches positive infinity, y swish vs. Google brain team announced swish activation function as an alternative to relu in 2017. Conventionally, relu has been the most popular activation function due to its gradient preserving property (i.e. Relu > scaled swish > swish > selu in this experiment, we added scaled swish into comparison (i found scaled swish in a reddit thread that someone said it performs better than original one). There is a large difference between training times even if swish performs better than relus on a problem, the time required to train a good model will be.
Advantages over relu activation function:
The authors find that by substituting the relu units for swish units, there is significant improvement over relu as the number of layers increases from 42. Having a by definition, relu is a monotonous and a smooth function as shown in fig. Activation function used by the yolo architecture is hard swish a variation of swish proposed by google brains in 2017, it looks very identical to relu but unlike relu it is relu vs swish source. Why the swish activation function. Third, separating swish from relu, the fact that it is a smooth curve means that its output landscape will be smooth. Experiments show that swish overperforms relu for deeper networks. The leaky relu and elu functions both try to account for the fact that just returning 0 isn't great for training the network. Like relu, swish is unbounded above and bounded below. These days two of the activation functions mish and swift have outperformed many of the previous results by relu and leaky relu specifically. Pourtant, comme vous le verrez en fin d'article, il y a des cas dans lesquels relu ou même swish sont meilleurs que mish. Conventionally, relu has been the most popular activation function due to its gradient preserving property (i.e. Google brain team announced swish activation function as an alternative to relu in 2017. Activation function relu leaky relu swish deep neural networks.
Asus Tuf Wallpaper : ASUS TUF Wallpapers - Wallpaper Cave - 1920x1080 asus tuf motherboard downloads wallpaper. . Find and download asus tuf wallpaper on hipwallpaper. Asus rog wallpaper hd republic of gamers wallpaper hd hd. We hope you enjoy our growing collection of hd images to use. Find and download asus tuf wallpaper on hipwallpaper. Asus tuf wallpaper 1920×1080 is free hd wallpapers. Desktop and mobile phone ultra hd wallpaper 4k asus, rog, logo, 4k, #4.309 with search keywords. Download wallpapers asus tuf gaming fx505dy & fx705dy, ces 2019, 4k. Asus tuf wallpaper 1920×1080 from the above resolutions which is part of the 1920×1080 wallpaper.download this image. Available in hd, 4k and 8k resolution for desktop and mobile. Download hd wallpapers tagged with asus from page 1 of. ASUS TUF Gaming Wallpapers - Wallpaper Cave from wallpapercave.com ...
Barcelona Country - Basque Country Highlights - Barcelona - Uniquest : Great savings on hotels in barcelona, spain online. . See actions taken by the people who manage and post content. Colección de tu almacén de lanas. Great savings on hotels in barcelona, spain online. Barcelona, the center of the catalonia region. Barcelona and its metropolitan area offer a wide range of public transport options, so you can get to this is a day when barcelona is suffused with a different atmosphere and it seems that everybody. Horario no se realizarán exámenes de conducción en las siguientes fechas (2021): All news about the team, ticket sales, member services, supporters club services and information about barça and the club. Barcelona and its metropolitan area offer a wide range of public transport options, so you can get to this is a day when barcelona is suffused with a different atmosphere and it seems that everybody. Tripadvisor has 3,265,511 reviews of barcelona hotels, att...
Desenho Simpson - Os simpsons - Desenho de elkabong - Gartic / When the animated tv series the simpsons first came out, nobody could image how successful it would become. . Desenho do homer simpson sendo feioto espero que gostem❤. Desenhos de personagens de cartoon. Последние твиты от the simpsons (@thesimpsons). Simpsons personagens desenho de personagens desenho dos simpsons desenhos filmes desenho tatuagem desenho animado ideias para desenho cachorro fantasias. Galinha pintadinha e peppa pig. Confesso que tirando a parte do. Desenhos para colorir dos simpsons / os simpsons, um retrato de família. .simpson / homer simpson desenho cartoon lucianoballack transparent homer simpson png desenhos similares a homer simpson esganando bart. Veja mais ideias sobre os simpsons, desenho dos simpsons, fotos dos simpsons. Veja mais ideias sobre os simpsons, desenho dos simpsons, fotos dos simpsons. P...




Komentar
Posting Komentar